除非您明确知道您在做什么,并且有十足的把握和信心想要这样去做,否则请不要轻易尝试本篇文章中提到的任何内容。我无法对本文中提到的所有细节信息负责,且无法保证其中的操作依然有复现的可能性,如果您依然需要执行类似的流程,请一切以官方最新的说明文档为准。
背景
随着满足我要求的第三台独立服务器的加入,我第一次拥有了一个三节点的 PVE 集群,这意味着这个集群满足了最小的「脑裂」避免条件,可以尝试使用 PVE 的高可用功能来提升关键业务的抗风险能力了。
目前我部署的很多服务都基于一套中心化的 OIDC 认证系统(未来我会讲讲为什么这么做),其中也包括了 PVE 集群本身的日常登录时使用的认证,本次我就是将它设置为了高可用的服务器。我希望能让它能做到在即使所在的宿主机出现了异常的情况下也能正常持续运行,从而避免对其他业务的稳定性造成冲击。
因为我弄不明白 k8s 的操作细节,所以就还是使用了更简单直观的 PVE 组建集群,以虚拟机的形式来运行它们。虽然效率比不上直接容器化运行,但对于目前的使用需求来说已经足够了。(补充: PVE 从 9.1 开始支持从 OCI 容器镜像创建 LXC 虚拟机,或许以后可以试一试)
准备工作
PVE 要求集群内的各个服务器拥有相同的版本,为了避免版本不一致可能导致的冲突,推荐先将 PVE 统一升级到最新的版本。
如果您需要涉及硬盘分区的变更,可能会需要抹去分区内的数据(取决于具体操作方式)。推荐先将宿主机上相关的服务先迁移到暂时不需要改动的服务器上,等待改动完成后再迁移回来,这样依次改动各个宿主机,就只需要延长传输等待的时间,而不会出现数据丢失的问题。
部署 Ceph 集群
在此次过程中,我绝大部分的时间花在配置 Ceph 和解决 Ceph 遇到的问题上(但直到最后也还是有遗留问题)。这并不是必要的—— PVE 的文档中提到只要将虚拟机的磁盘文件放置在共享存储上即可。使用 Ceph 只是因为 PVE 对它提供了较好的原生支持,并且可以充分利用三台服务器之间互相的冗余保护机制。
准备虚拟局域网
Ceph 要求所有宿主机在同一个网段里,这意味着不能像 PVE 那样直接将离散的公网 IP 地址用作集群间相互访问的入口。我使用 Nebula 组建了一个虚拟局域网,您也可以选择您熟悉的方案,例如 Tailscale (WireGuard) 之类。
安装 Ceph
当虚拟局域网搭建起来之后,就可以在宿主机里安装 Ceph 了。
安装 Ceph 是一个系统层级的操作,所以如果您使用 PVE 的图形界面来安装和初始化,需要使用 Linux PAM 进行宿主机身份认证。如果您先前出于安全考虑在策略中禁用了这个用户,请记得将它重新启用,在一切配置完成后再恢复禁用状态。您也可以使用 SSH 连接到服务器进行命令行层级的操作,但我并没有尝试过这种方案,所以不知道应当如何具体操作。
如果您和我一样是一般用户而非企业订阅用户,请在安装的渠道选择中选择 Non-Subscription ,以避免出现安装错误等问题。
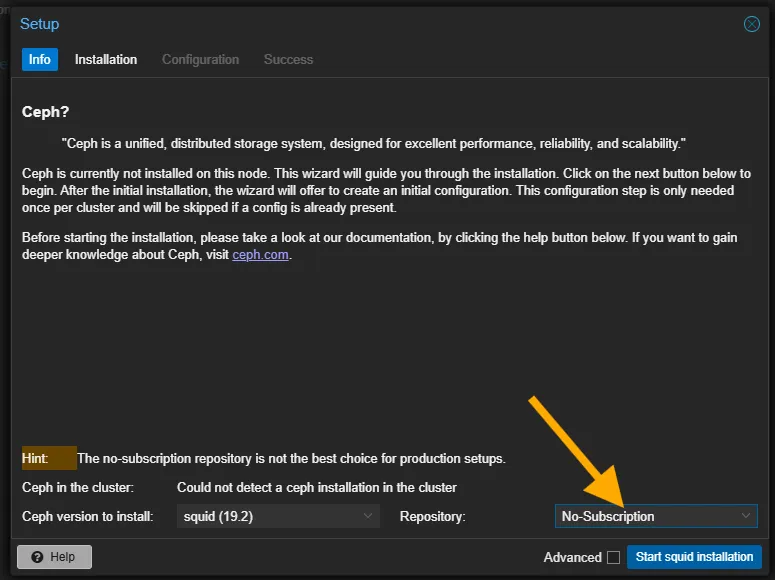
在 Installation 界面中,您需要在弹出提示消息后按下回车键以确认启动安装。安装完成后状态可能不会及时更新,您可以尝试刷新浏览器来完成安装后的初始设置流程。
在配置完成后,如果您有什么想要改动的内容,您可能无法直接在 PVE 界面中对配置文件进行调整。此时您可以直接编辑宿主机的 /etc/ceph/ceph.conf 文件, PVE 会自动将最新的配置分发给集群内的其他节点。
添加 Monitor 和 Manager
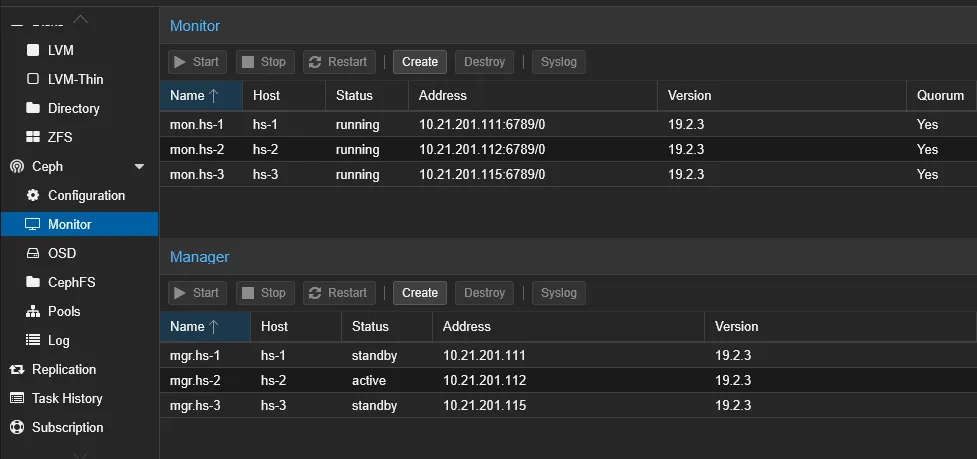
当 Ceph 安装完成后,我们需要为它配置状态监视器和管理器。因为三个服务器之间彼此都是对等关系,所以三个服务器都可以作为 Monitor 同时也是 Manager 。
Monitor 应该默认会在 Ceph 配置的时候自动添加进去(后面也可以改动),但 Manager 需要手动添加。当三个节点都添加进去之后,就可以看到 Monitor 的状态都是 running ,而 Manager 中只有一个是 active ,其他的都是 standby :
准备硬盘
Ceph 推荐的配置方式是使用整个硬盘作为 OSD 设备,以实现更精准的资源管理。但由于我的服务器并没有那么丰裕的资源,所以我选择的是从每个磁盘里划出一小块空间来作为 OSD 分区使用。
对于已经写入过数据的分区, Ceph 可能会无法成功识别。此时您可以使用宿主机菜单的 Disks 部分的 Wipe Disk 功能来抹去分区上的数据和标记,使它可以被 Ceph 用作 OSD 设备。
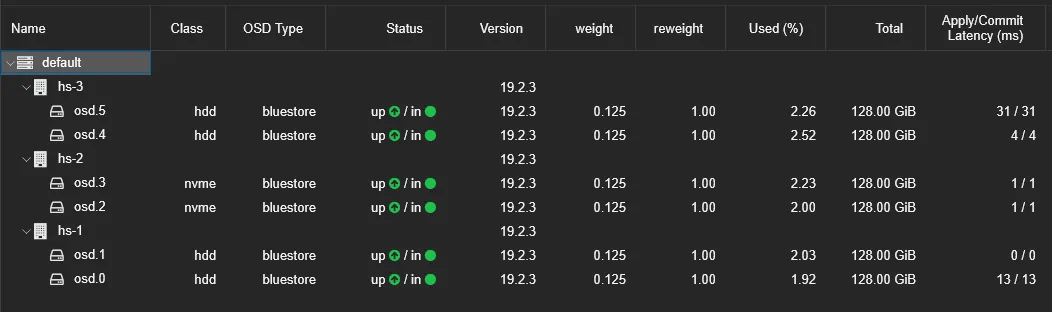
由于我的每个设备上各有两个硬盘,所以我从两个硬盘里都各自划分出了一部分等大的空间,以便更好地利用它们提供的冗余资源。
创建 OSD
OSD 是 Ceph 里用于存储数据的基本单元。在每一台宿主机上,我们都使用在 准备磁盘 节准备的磁盘分区来配置 OSD 。配置完的 OSD 有一个启动的过程,当它启动完成后类型就会变成 bluestore ,状态则是 up / in 。
调整 Crush Rule
对拥有多个 OSD 的宿主机来说,默认的以 host 作为管理单元的 replicated_rule 可能会导致出现 x pg undersized 健康报错(x是一个具体的数字)。为了避免这个问题,根据一个来自 StackOverflow 的回复,我们可以使用 Ceph 内置的模板,创建一个以 OSD 作为管理单元的规则:
1 | ceph osd crush rule create-replicated replicated_rule_osd default osd |
创建 Pools
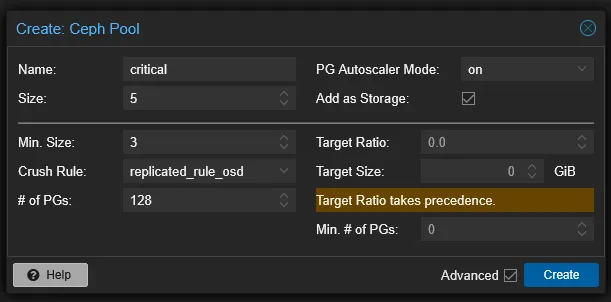
在 Pools 页面可以创建存储池,也就是实际用于存储数据的位置。它会将数据根据指定的规则将 pg 分配到不同的 OSD 上,来实现稳定的存储。
不同的 Pool 支持配置不同的 Size 。例如,默认的 3/2 的意思是数据会被重复 3 份,当最少有 2 份可用时可以保证数据的可用性。我有 3 个节点 6 个硬盘,所以我对关键数据的 Size 设置是 5/3 ,也就是将数据重复 5 份,保证最少 3 份可用。通常请确保最少可用数 ≥ 大小的一半,以避免出现数据错乱的问题。
在高级选项中可以调整 Crush Rule ,我们选择刚刚创建的 replicated_rule_osd 即可。
有些参考资料里可能会提到需要添加 Metadata 和创建 CephFS ,但我发现它好像暂时用不到(这个似乎默认情况下是用来存备份文件的),所以配置是配置了,但是没有启用。方法也很简单——把全部三个节点都设置成 Metadata Server ,然后就可以创建 CephFS 了。
调整业务的访问方式
对于高可用的虚拟机来说,它因为可能会在不同的宿主机之间迁移,所以它的 IPv6 地址可能会发生变化(我使用的是从一个 /64 段里用 SLAAC 方式分配给各个虚拟机的),这就意味着要么预先知道所有可能的 IP 地址来做带错误检测的负载均衡,要么就是使用一些从业务反向连接到流量入口的连接方式。我使用了后者,选择让 frp 来提供这个功能。
frp 的设置并不复杂,只需要配置好服务端和客户端就可以快速启用。因为这边的 frp 仅仅是用来提供 HTTP 代理的,所以选择了使用 docker compose 的方式运行。
- 服务端暴露 7000 端口用于来自客户端的连接,并将 vhost 的 8080 端口暴露在本地,以方便 Caddy 作为网页服务器连接到它;
- 客户端方面,为了方便使用了 host 作为 network_mode ,以简化到各个具体服务的连接配置。
配置完成后,可以先尝试访问一下服务,检查是否配置正确,确保没问题的情况下就可以执行下一步操作了。
迁移服务器硬盘
为了使用高可用的功能,需要把存储在设备本地的虚拟机硬盘迁移到刚刚建立的 Ceph 存储中。这个操作并不困难,就是可能是由于我的 Ceph 存储池是跨大洲的,还有机械硬盘的参与,所以它的读写速度慢得离谱,写入均速不到 5MiB/s ,这速度放在 2025 年实在有些过于荒谬,可以说和好用完全不相关了。
能迁移的就只有服务器的磁盘,虽然 CloudInit Device 也是作为文件存储在宿主机本地存储里的,但它不可以迁移,在服务器被新的宿主机启动的时候也会自动重新生成,所以不用在意它。
为服务器配置 HA
当一切准备工作完成之后,就可以开始为虚拟机配置高可用规则了。事情到了这一步其实就非常简单了:去 DataCenter 的 HA 里,在 Resources 中添加 VM 就行。
- Max Restart 表示在一台宿主机上最大的重试尝试次数。如果超过了这个阈值,虚拟机在这一轮就不会再尝试在这个宿主机上启动,而是想办法移动到其他的宿主机上去尝试。
- Max Relocate 表示最多可以去几个不同的宿主机上尝试。如果超过了这个阈值,这一次启动就会被标记为失败的,如果配置了告警规则那么也会触发相应的内容。
- Request State 表示希望虚拟机是什么状态。默认的 started 表示希望它是启动着的。
全部配置完成后,稍等片刻就可以看到虚拟机会被自动启动,这就是 HA 规则在起作用了。
而当宿主机确实出现问题的时候,就可能会出现类似这样的虚拟机高可用启动提示:
同时可以观察到虚拟机迁移到了另一个节点上去了。