今天下午 3:10 ~ 5:18 ,我们的其中一个实例站 eihei.net 经历了一次建站以来最严重的宕机事故,最长的业务宕机时间超过 2 小时。虽然目前站点已经恢复,但由于其部署的服务器存在物理上的局限,当等到资金资源足够的时候,我们将考虑把所有的相关服务全部撤出目前的这台垃圾服务器,从而避免再出现像今天这种算是负面机缘巧合导致的意外宕机事件。
关于本次的宕机,我们将原因归结于以下几点:
- 操作人员失误
- 服务商超售严重,性能缩水,CPU steal 起飞
- 硬盘阵列爆炸过,质量堪忧
- (存疑)接入大型中继导致实例负载过高
以下的部分,将根据时间顺序,依次梳理本次事件的全部过程。
起因:站点频繁离线
事实上这并不是第一次出现意外离线的情况了,在 4 月中旬开始,站点就会每隔几天不定期出现宕机或是反应缓慢的情况,有时会被状态监测系统捕获,有时则只是用户主观感受,并未出现严重的连接超时情况。
根据监测系统的记录,近段时间站点的平均反应时间接近了 1.5s 。
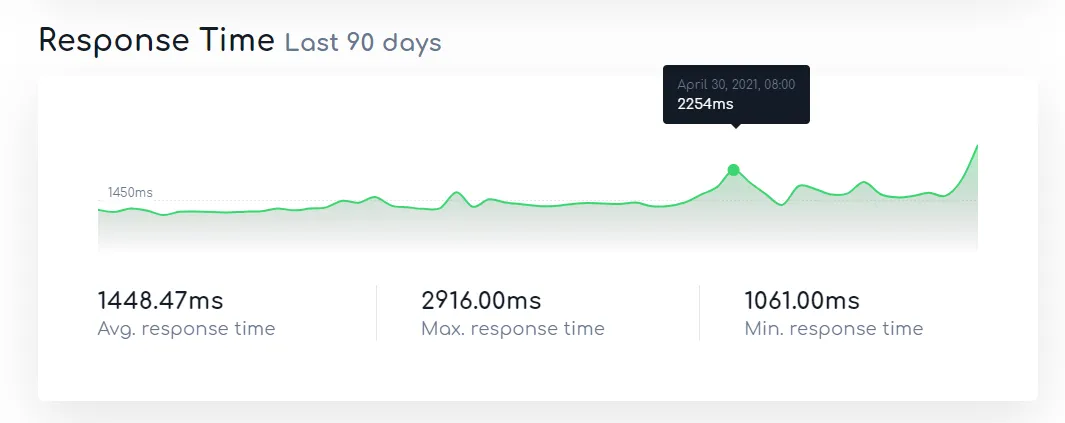
而我们的主实例站 nya.one 的平均反应时间则只有 300ms 左右。
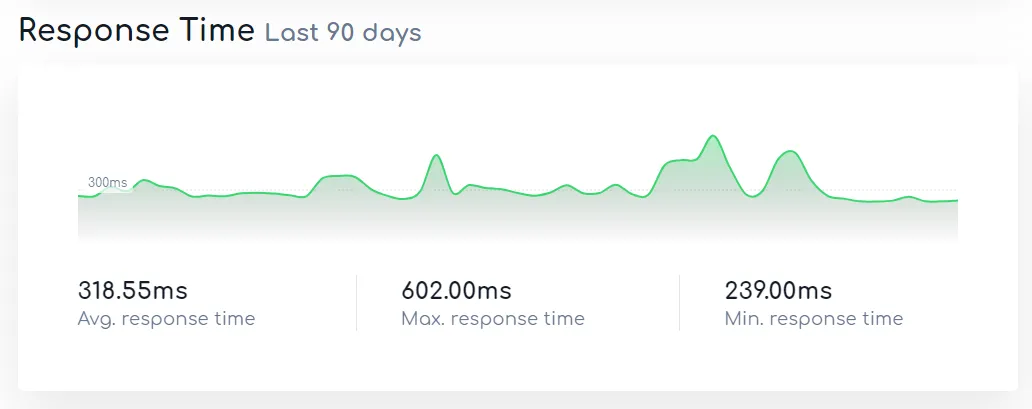
虽然我们觉得可能是和地理位置有关,但同样位于欧洲的静态文件存储桶,则只有 125ms 左右的平均响应时间;也曾怀疑是否和 Mastodon 的高消耗占用有关,但根据 o3o.ca 的响应时间来看,最大也不过只有 400+ ms。即使是考虑 OVH 的网络,但也有不少实例(包含 nya.one )承载于 OVH 网络之上,但从未听说有什么奇奇怪怪的情况发生。并且作为国际级的大型服务器提供商,OVH的网络也完全不会成为瓶颈。
考虑到这台服务器的处理器是 AMD Opteron 6128 ,一款 11 年前发布的极致典藏古董处理器,我们觉得主要的原因,应该还是由于服务器性能严重不足引起卡顿,进而导致愈发严重的丢包直至失去响应的情况发生。
再加上硬盘阵列曾出现过爆炸导致服务器失联、重启锁盘的情况,我们也怀疑有很大可能,是因为这些破烂硬盘出现了难以挽救的糟糕问题。

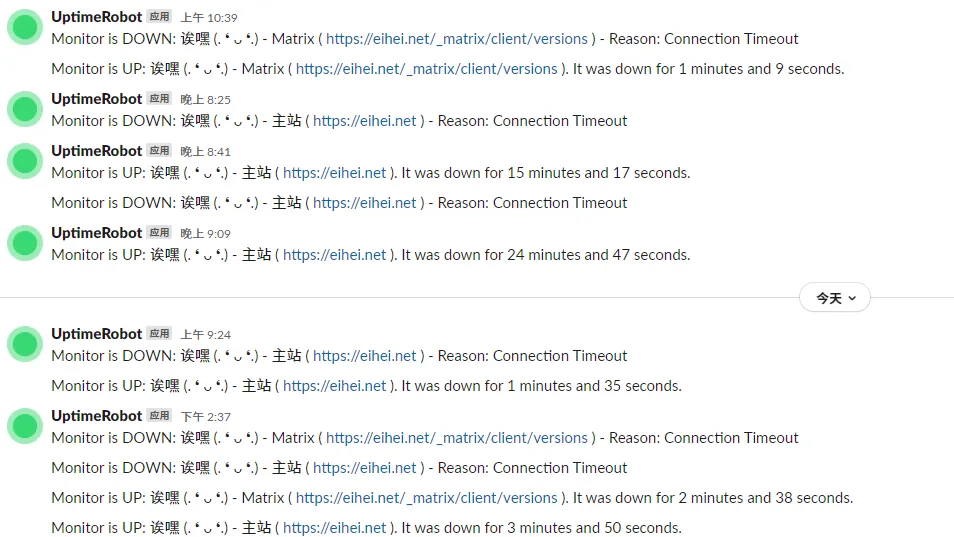
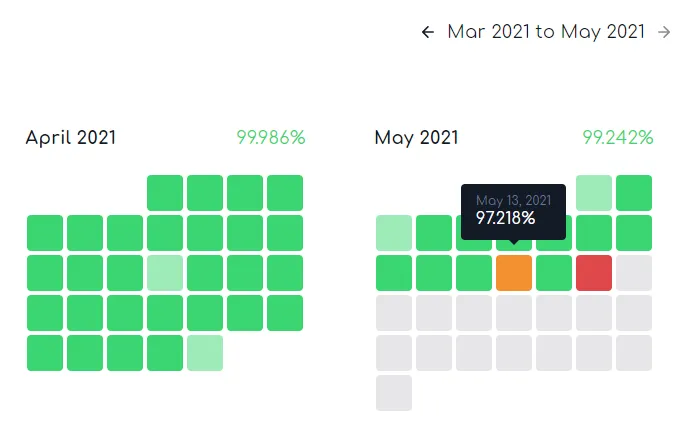
直到今天,我们觉得这样的情况应当要进行介入处理了。 Mastodon 即将发布 v3.4.0 正式版,我们也应当为这个大版本更新做好对应的准备工作。所以当卡顿再次出现的时候,我们在控制台上输入了重启的指令。而这,则是一切噩梦的开始。
重启:噩梦伊始
输入 reboot 后,意料之中的 SSH 连接中断并没有很快出现。虽然大概有些怀疑,但这时的我们并没有意识到问题的严重性,还以为只是网络丢包导致断开连接的数据包没有及时返回。但几分钟后,当尝试开启一个新的连接时却发现根本无法连接,提示连接超时,不得已,登录到服务商提供的 VNC 上试图检查,发现事情隐隐约约有些不对劲之处:
服务器正在运行关机例程
包含但不仅限于结束容器服务、回收系统资源、保存随机数种子等等一系列平时难以见到的底层操作。而这反应速度,我甚至一度怀疑我是把我开发板上的系统连接上虚拟机了。
惊讶之余,更多的是懊恼为何没能及时意识到此事件的发生——早该在服务器失去响应的时候就料到它关机失效的。现在说什么都晚了,一时也没想到什么方便的通知方式(并且也来不及了),所以就一边罗列着待办事项,一边顺带等待服务器的重启完成。
经过十多分钟的艰难等待, VNC 的屏幕变黑了。
开机:届不到的引导
本以为至少开机的负载不大,希望能够稍微顺畅一点,但可能好巧不巧的正赶上其他用户疯狂挤占 CPU 的最后一丝性能,连试图加载出可以引导的选项,看上去都是那样的艰难苦困。甚至不知为何,它加载到了空无一物的虚拟光驱,之后便是光标闪烁的无尽空虚。茫然无措的我们,只能寄希望于界面上唯一的 “Send CtrlAltDelete” 字样,试图用跨越世界的力量,唤起虚拟机最后的一丝良知——很可惜,它的灵魂早已被支配,留给我们的,只剩下一副双目无光的空荡躯壳。
那就从头开始,再试一次——一边这样想,我们去控制台向它发送了软重启命令。但失去响应的它,对于我们的呐喊毫不理会,依旧我行我素地一味闪烁着失去梦想的光标。
那就只能这样了!强压下心中的焦急与五味杂陈,我们向它发送了硬重启命令。
很可惜,毫无波澜。
然而,不知是冥冥之中产生了意念的指引,还是一次太阳风暴的偶然乍现,正当我们手足无措之时,不知为何系统突然开始尝试从硬盘引导系统。惊喜之余我们也关闭了工单页面的诉苦,掏出整理的笔记,开始准备下一步的恢复工作。
容器:双刃的剑
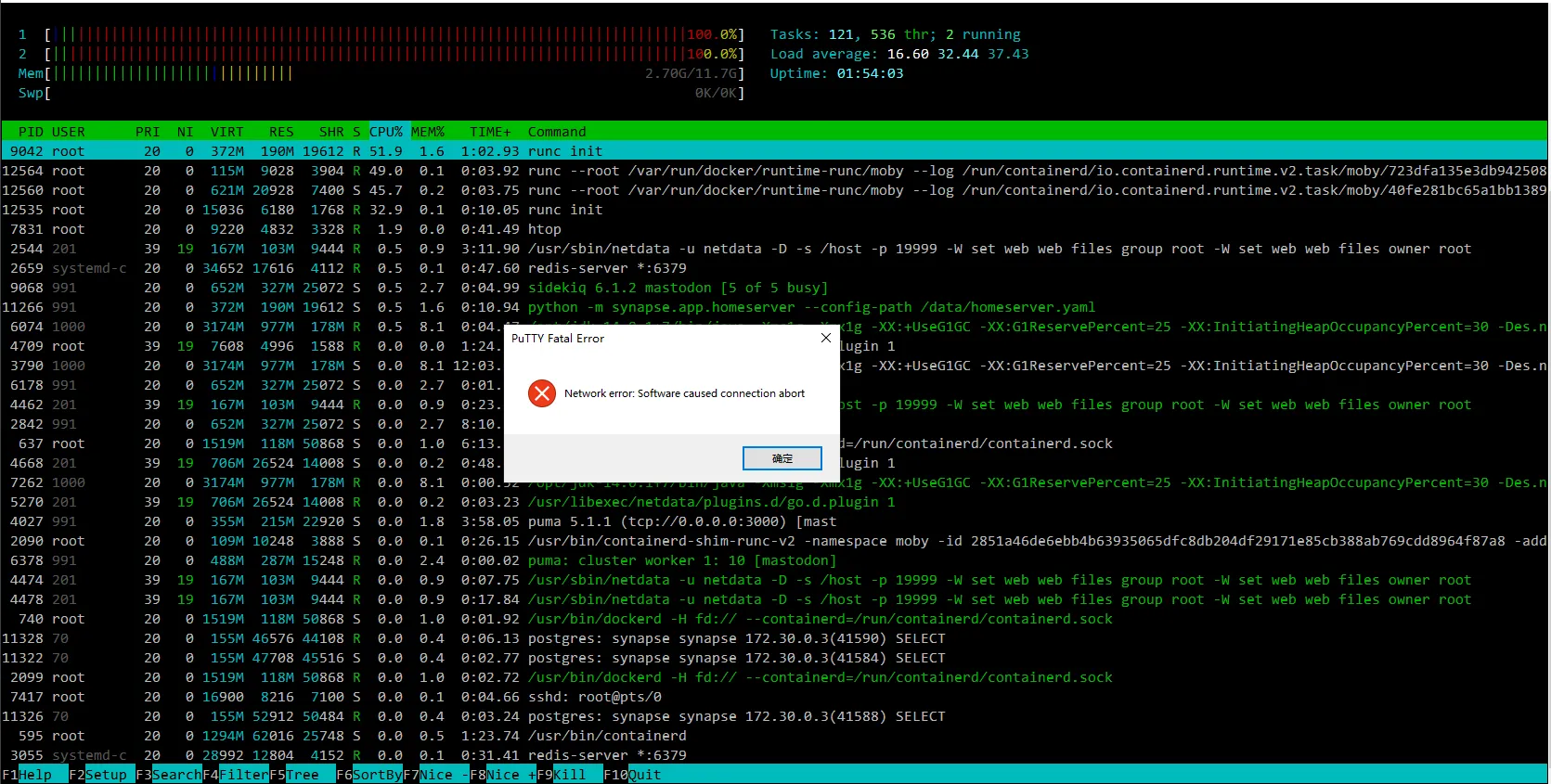
使用容器部署服务,对于无论是安全性还是可维护性、亦或是备份与迁移的方便程度而言,都不失为一种相当优异的方案。唯一可能的困惑,恐怕就只剩下多一层包裹是否会带来性能损失的担忧了。 Docker 很强大,但 2010 年可没有 Docker 。启动容器环境本身,对于现代的处理器来说完全不成问题;但对于过去的处理器而言,似乎成为了一个不小的挑战。诚然,这块 CPU 已经是 AMD64 指令集支持的型号了(我想这就是为什么这台服务器还没被淘汰的原因吧),但在发展日新月异的计算机面前,一个 decade (十年) 的代价实在是过于沉重,沉重到当年的辉煌,如今在轻轻的负载下即可成为一滩只会发烫的废铁。在 htop 窗口的记录中,仅仅是为了启动 Docker 的底层环境, CPU 的占用率就长期保持在了 100% 。
于是非常有幸地,我们观摩到了 Docker 底层启动的详细过程,包括平时不会注意的网络层驱动的初始化、容器附属环境的启动、系统相关事件的注入等等等等。同时随之而来的,也有大量设置 restart 为 always 的服务的跟随启动。至少在这突如其来的黑暗之中,我们看到了一丝希望的光芒。
超时:没有硝烟的战争
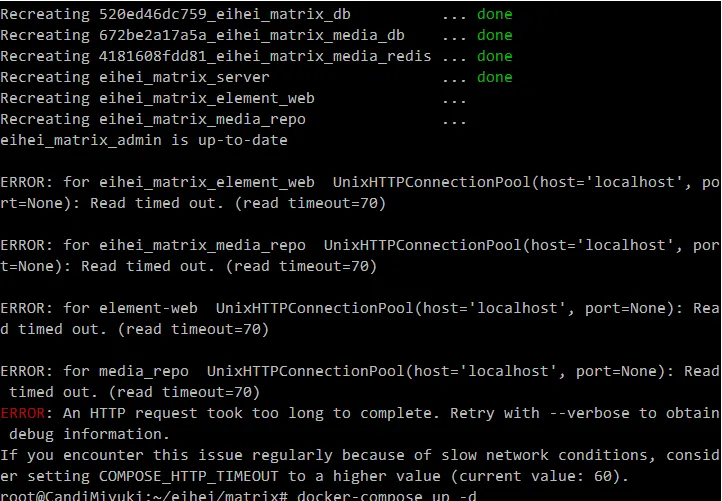
由于服务启动实在过于缓慢,有大量容器因为依赖没有完成启动而启动失败,从而导致不断的尝试或是崩溃,进一步加剧了服务器的卡顿。平时一句简简单单的 docker-compose up -d ,如今竟成了压倒服务器的最后一行指令,绿色的 done 犹如施舍一般不情愿地出现,更多的仅仅只是卡在了暗红的 ERROR 便不再活动。于是只能一遍一遍地启动,哪怕每次只启动一项服务也好啊——这样想着,这样做着,这样重复着,直到不再有错误返回,终于能长舒一口气:至少,它们愿意动一动了。
等待:最遥远的距离
世界上最遥远的距离,莫过于满怀着虔诚敲下了一行指令,那边便再无回音。只能一次又一次地刷新页面,试图在 502、521 等出现或是空白页面的错误提示中,寻找到那一丝有效加载的希望。一边是监测平台辅助我们进行监测管理,另一方面是我们手动的请求,怀揣着愧疚与虔诚,期待着希望与转机,F5 的起起落落与路由器上信号灯的闪烁见证着我们的决意。
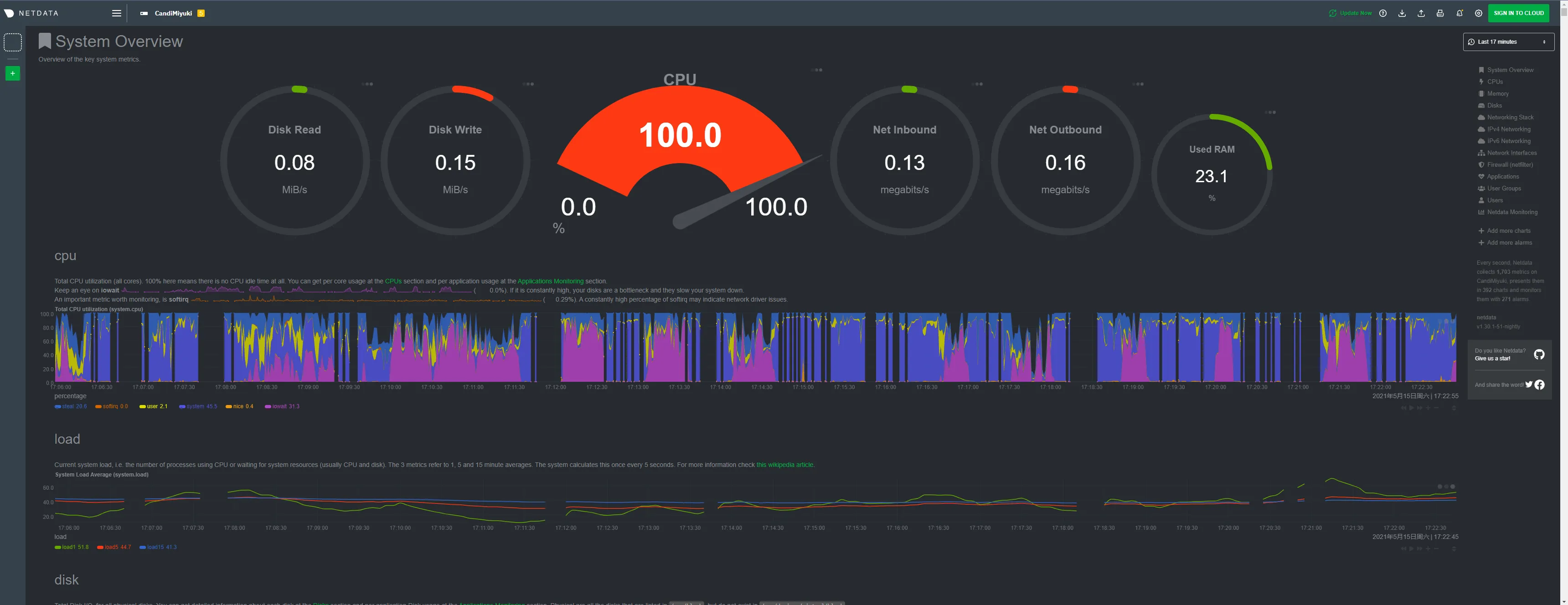
netdata 的加载需要时间,而加载出界面之后还要获取数据,更需要时间;而当我们发现甚至连 netdata 都已经到了无法采集到所有数据的情况之后,好不容易悬起的一丝希望,又只能被狠狠摔在地上;
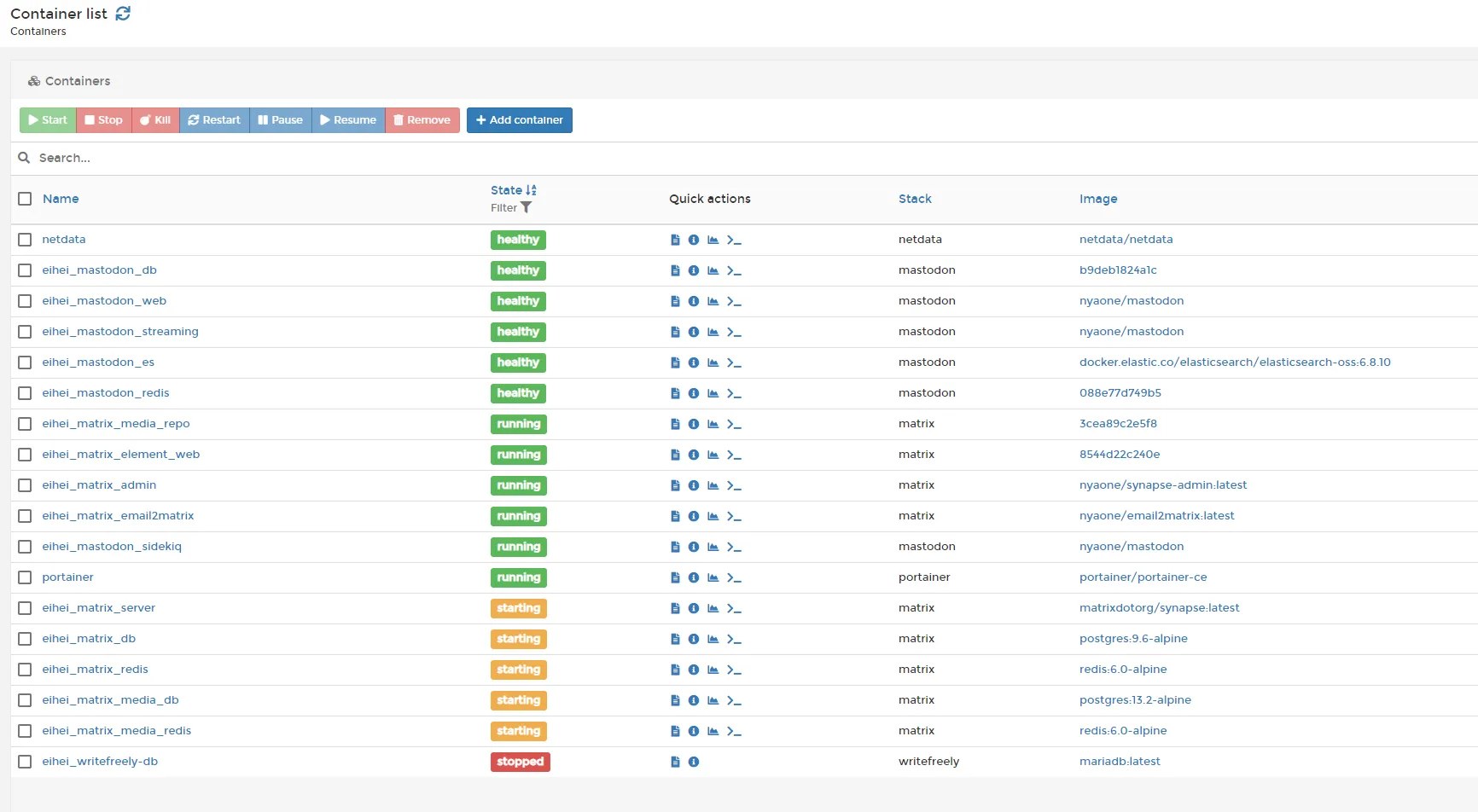
portainer 的加载需要时间,而加载出界面之后,等待进入 localhost 进行管理,则更是需要一大段一大段用于通信的时间;而当在无数次 504 Gateway Timeout 的错误被毅力克服后,我们得到的,却只有些许 stopped 、些许 starting 、些许 unhealthy 和终于能让我们稍微安心一些的些许 healthy 。
在漫长的等待过程中,我们因为到了饭点,去简单吃了个饭。
而当走在路上时, Slack 上传来的上线消息提示,对于我们而言,不光是这几个小时的成果认可,更像是一种温馨的宽慰吧。
到 5:18 ,所有的服务启动完成,我们准备开始检查是否出现数据的损失。
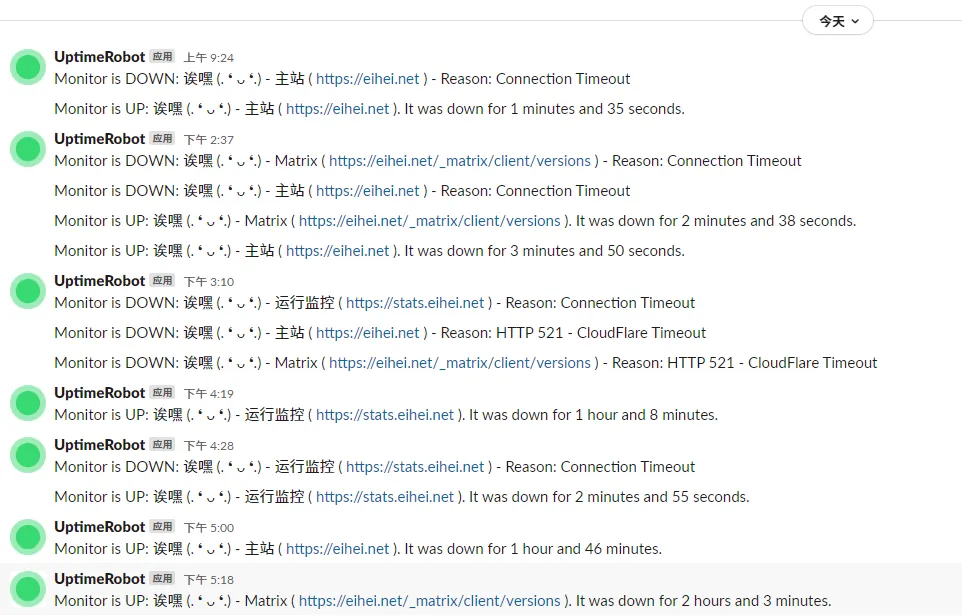
虽然,由于服务器还是非常不稳定,因而在突然的某个时刻,用于监视资源状况的连接也被断开了。
后记:恢复与升级
预想着顺带就做一下 Matrix 部分的升级工作,于是就把顺带着升级了一下。当然,这速度确实也是不能用的,因为实在是太卡顿了——上面的某两张截图,其实就是现在才截的。即使是这么多小时之后,它的性能照样是那么拉跨,一点都没有恢复。
我们退出了一个大型的中转实例,不知道会不会是因为那边带来的负载过高,导致服务器没法正常响应。
服务器还是那么烂,基本可以说是没法使用的地步了。说句难听的,我开发板上跑的嵌入式 RISC-V 的嵌入式 Linux,或是路由器里跑的自编译 OpenWrt 都没这么卡。但由于是测试性的社区,并且目前没有资金用于升级更新更强大的服务器,所以就先继续这样使用着吧。
有预料的,当 Mastodon 升级 3.4.0 版本的时候,又将会是一大场腥风血雨。